當神經網路訓練完成後我們想要知道到底成不成功,輸出的「準確率」可以告訴我們,但有沒有方法可以變得客觀呢?這時候我們就會使用到「損失函數(Loss Function)」,損失函數是在機器學習和深度學習中的一個重要概念,用來衡量模型預測和實際目標之間的差異或誤差。損失函數通常用於訓練機器學習模型,以幫助模型調整權重和參數,以使損失函數的值最小化。
下面介紹兩個常用的損失函數:
MSE 的計算方式如下:
數學公式表示如下:
MSE = (1/n) * Σ(y_pred - y_true)^2
MSE 的值越小越好,當 MSE 趨近於零時,表示模型的預測值非常接近實際目標值。MSE的想法非常簡單,且容易計算,不過它也存在著缺點,MSE 對極端值很敏感,因為它將差異平方,這可能導致極端值對損失的影響很大。
交叉熵損失的計算方式如下:
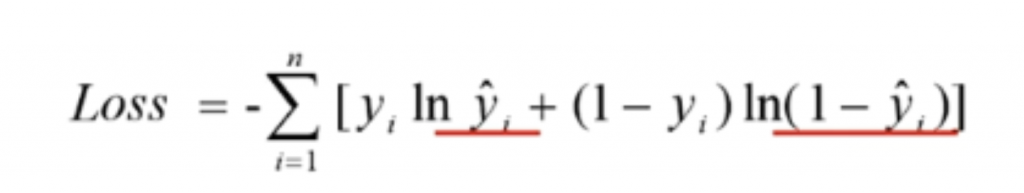
交叉熵損失的值越小越好,它衡量了模型預測的概率分佈和實際標籤之間的相似度。當模型的預測概率分佈接近真實標籤時,交叉熵損失趨近於0,表示模型性能較好。


 iThome鐵人賽
iThome鐵人賽